Die OCR Erkennung ist bei mir ungenügend! Nur Buchstaben- und Sonderzeichensalat.
Omnipage dagegen liefert tip-top Ergebnisse. Mache ich etwas falsch?
Moin @haku448
Der Fehler ist bekannt und die Kollegen aus der Entwicklung haben schon eine Lösung im Blick. Ein genaues Veröffentlichungsdatum für das Update haben wir allerdings leider noch nicht.
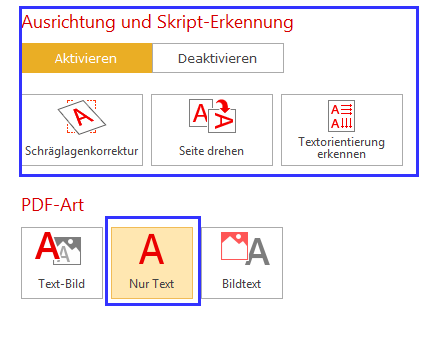
Grundsätzlich kann helfen, in den OCR Einstellungen unter PDF-Art "Nur Text" zu wählen und die Funktionen unter Ausrichtung und Skript-Erkennung auszuschalten, falls diese nicht für die Datei benötigt werden.
Beispiel (Bild)